Description
TrackCore-F is a methodology and collection of techniques to deploy Machine Learning (ML) models involved in ML-assisted particle track reconstruction algorithms on FPGAs. With TrackCore-F, the focus is the deployment of the ML model element, specifically aiming at the Transformer architecture. As such, FPGA-accelerated inference can boost tracing performance by reducing the computation latency. The small form factor and low power requirements of FPGAs enables on-site installation and paves the way for potential online tracking, as opposed to current post-mortem approaches. Currently, TrackCore-F operates to convert pre-trained models taken from the project TrackFormers as input. However, the techniques to convert and evaluate common Transformer blocks, e.g., encoder layers, are generally applicable.
Development workflow
Achieving deployable syntheses for pre-trained ML models will require going through multiple steps, performing analysis, and involves a variety of tooling. We consider models expressed in PyTorch model format as the starting point. FPGA deployment will also demand considerations and deciding on a full or partial acceleration. Either strategy can be motivated based on different factors, some being use-case dependent. The complete development workflow for a partial acceleration is depicted in Figure 1.
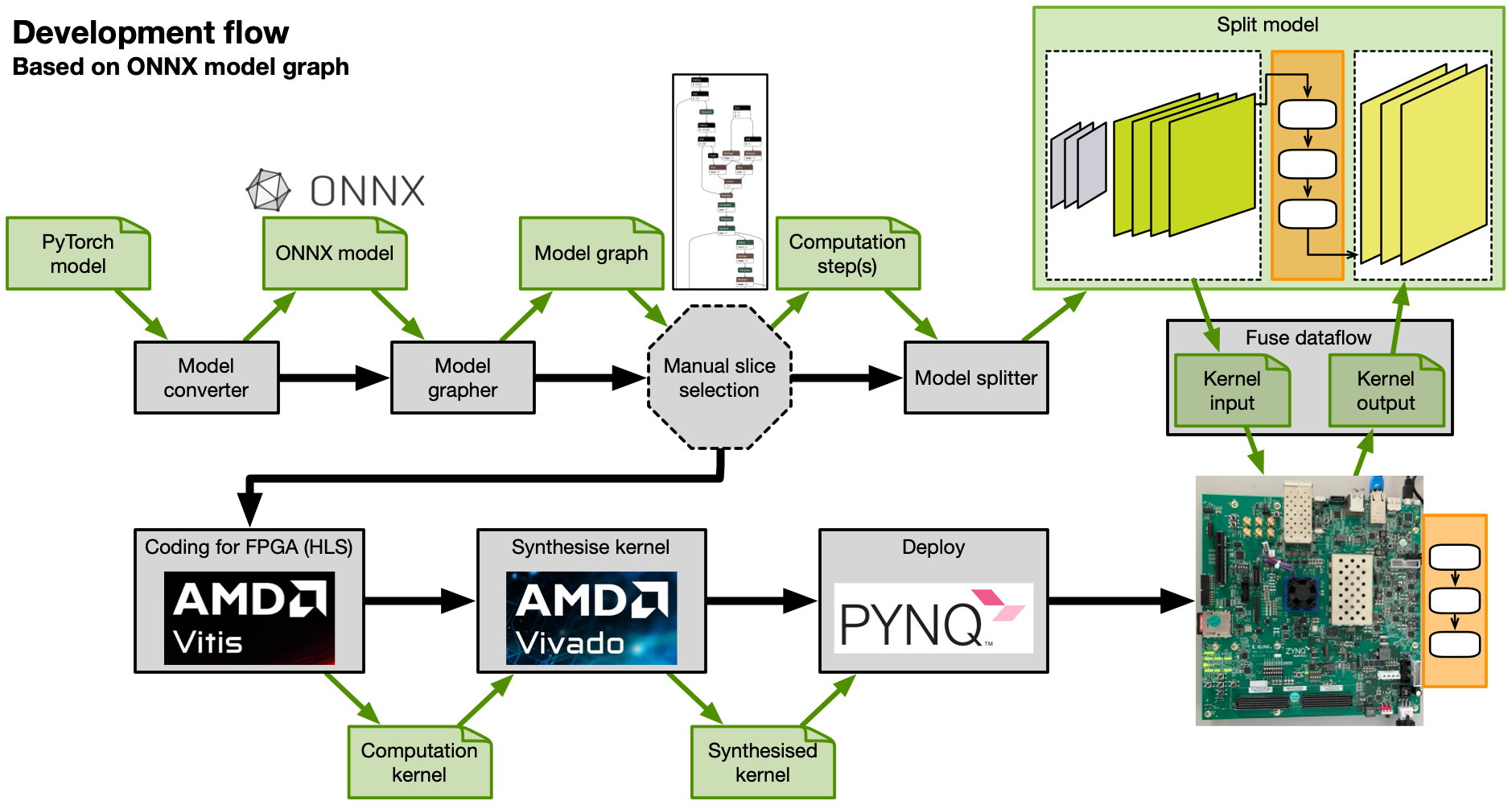
PyTorch model format does not provide granular visibility and individual access to a model's internal computational steps. By converting the model to Open Neural Network Exchange (ONNX) format, a detailed model graph can be extracted. Partitioning the model into separate slices is done in Python. This is followed by coding a computation kernel in HLS, synthesising this kernel, and deployment using AMD Vitis HLS, AMD Vivado HLS, and PYNQ, respectively. Further details can be found in our EuCAIFCon 2025 proceedings paper [1].
Feature set
In its current form, TrackCore-F is more of an experimental workflow than a reusable tool. The below listing covers targeted functionality for a reusable version. Current availability is indicated using status markers.
Orange: Limited selection
Red: Under development
| Category | Feature | Status |
|---|---|---|
| TBA | TBA |
|
| TBA | TBA |
|
Code repository
TBA ...